DTeam 技术日志
Doer、Delivery、Dream
Dust:当Truffle遇上数据库开发
以太坊开发中,Truffle 几乎是事实的标准,用它可以方便地开发、测试和部署智能合约。虽然它一直对外宣称 Dapp 开发框架(隐含前后端一体化,结合 node),但我认为它最大的功绩就是将合约的整个生命周期有效地管理起来。因为,考虑到不同项目团队偏好的技术栈不一样,前后端完全可能是另外一套完全不同的选择。但合约开发,你没得选。
因此在我看来,稍微复杂的区块链项目基本组成如下:
- backend,后端服务
- frontend,前端 UI
- contract,合约工程
这里的合约工程即是 Truffle 大显身手的地方,虽然你也可以在一个使用 web3j 的后端工程中包含和管理合约,但我认为这种方式远比不上用 Truffle 来得方便。
从这个模式中是否看到传统项目中类似的场景,比如项目中数据库制品的管控,即项目中数据库部分的开发。稍微复杂一点的项目都会涉及到存储过程、触发器等数据库制品的开发。并且,对于创业项目,其早期应该尽可能采用简单架构,避免一上来就是微服务、事件驱动。用一些数据库的方式解决问题,看似老旧和扩展性存在瑕疵,但好处是实现快速,节约了人力和时间。待概念验证成功,开始盈利之后在做迁移也不会有太多问题。况且,如果对这部分有良好的管控,对于后期迁移也是好处多多。
本着这样的想法,我开始思考是否可以将 Truffle 的模式引入到传统项目的开发中,用类似的工具管理项目的数据库制品,于是一个 Demo 性质的工具诞生了:dust。这样,一个项目的结构就变成:
- backend,后端服务
- frontend,前端 UI
- database,dust 工程
明眼人会提到,目前已经有类似 flyway 这样的 db migration 工具可以帮助我们来管理项目中数据库部分,那为啥还要有 dust 呢?这是个好问题!也正是因为有这样的疑问,dust 也仅止于 demo 程度,只是用来满足我看到 Truffle 之后想要实现类似工具管理项目中数据库制品的“心瘾”。
不过,相比起 flyway,dust 还是有一些不同之处:它集成了一组成熟的工具集,并提供了一套解决方案来管理数据库制品的整个生命周期,即:“创建 -> 测试 -> 部署 -> 升级”。甚至它也将 flyway 也纳入其中,作为其底层支撑。
dust 集成了:
- cli,picocli
- 自动化测试,spock
- 本地数据库测试环境,testcontainers
- 轻量级的 DB Migration 工具,flyway
它的基本使用非常简单自然:
- 创建 Dust 工程。
- 开发数据库制品,如表、存储过程、函数、任务、触发器等。
- 完成相应的测试代码。
- 本地运行测试。
- 部署数据库制品到不同的环境。
关于其详细使用,可以访问它的github 仓库。在后续的内容中,我将简要说明一下 dust 的实现机制,满足有兴趣进一步了解其细节的读者的胃口。
CLI
dust 是一个 cli 应用,因此选择好的 cli 框架会让整个事情事半功倍。在 Java 工具集中,picocli 算得上是颜值担当,不仅支持常见 cli 系统的命令语法,而且还支持色彩。其实现效果并不比其他平台中流行的 cli 框架差。
dust 本身的命令系统并不复杂,标准的:Command + SubCommand 的实现,这一架构可以用 picocli 轻易做到。而且,还自动生成帮助系统,如下图。
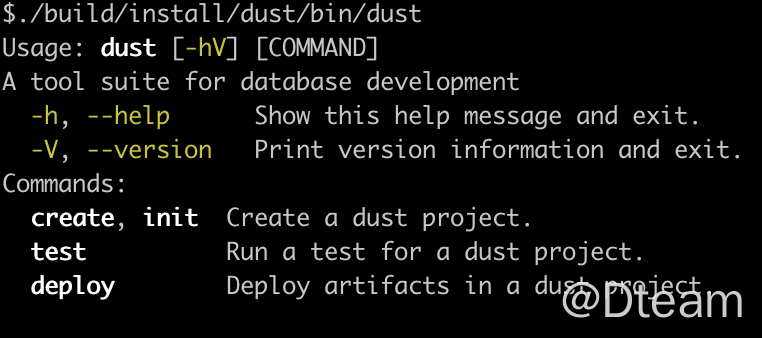
具体实现请参见 picocli 文档和 dust 的实现。
dust 工程
dust 工程(使用 create 子命令创建)本质上就是一个 gradle 工程。创建它的过程很简单,就是从 dust 执行文件中资源的工程模板复制到指定目录即可,参考下面的代码:
private void copyFolder(Path dest) throws IOException, URISyntaxException {
Path src = FileSystems.newFileSystem(URI.create("jar:" + getClass()
.getProtectionDomain()
.getCodeSource()
.getLocation())
, new HashMap<>()).getPath("/template");
Files.walk(src).forEach(source -> copy(source, dest.resolve(src.relativize(source).toString())));
}
private void copy(Path source, Path dest) {
try {
Files.copy(source, dest, REPLACE_EXISTING);
} catch (Exception e) {
e.printStackTrace();
}
}
有了模板工程,又因为是 gradle 工程,有经验的开发者几乎可以不再需要使用“dust”命令了。但是,我想更进一步,就如同 Truffle 本身也是 NPM 工程,但也一样能用“Truffle deploy”这样的方式运行。
实现这一步有一个投机取巧的方法,事先在模板工程中写好相应的 gradle task,接下来用 picocli 的 command 封装,直接在程序中触发 gradle task 调用即可。这里就用到了 gradle-tooling-api。但这里需要留意向 task 传入参数的方法,代码如下:
@Override
public void run() {
Path projectPath = Paths.get(".").toAbsolutePath().normalize();
try (ProjectConnection connection = GradleConnector.newConnector().forProjectDirectory(projectPath.toFile()).connect()) {
connection.newBuild().forTasks("deploy").setJvmArguments("-Dexec.args=" + datasource)
.setStandardOutput(System.out)
.setStandardError(System.err)
.run();
}
}
留意其中的 setJvmArguments。
这样,你就可以用类似“dust deploy”的方式来触发 build.gradle 中 deploy 任务的执行了。这同样是 grails 这类框架的实现思路。
测试代码
这部分很简单,因为模板工程中引入了 Spock 依赖。在使用时,开发者只需在 test 目录下创建 spock specification,然后运行“dust test”就能触发。当然,其背后仍然是触发“gradle test”这个任务啦。
本地测试环境
一般来讲,涉及到数据库的测试环境都不那么友好,然而 testcontainers 的出现给大家带来了一丝曙光。其原理跟上面说的一样,引入相应依赖,直接在测试代码中使用即可。最后由“dust test”触发。
部署脚本
部署采用的是 flyway 的 Java-based migrations,同时也采用其命名规范。我个人推荐“Versioned Migrations”,不建议采用“Repeatable Migrations”。因为在实际情况中,后者使得制品历史消失了,本身已经违背了引入 Migration 的目的。而且,DML 类的变动总涉及到数据的迁移,因此坚持“一直前向”是最适合的策略。而且,为了避免频繁修改脚本,我建议不要在项目早期引入 dbmigration,而是待数据库制品都相对稳定时,再开始不迟。
为了达到类似 Truffle 部署脚本的效果,项目模板工程预置了三个文件:
- DustBaseMigration.java,部署脚本基类
- DustConfiguration.groovy,部署的环境配置加载类
- MigrationApp.java,flyway 部署执行类
- 注:为什么不直接在工程模板中引入 gradle flyway 插件?原因是我想尽可能给用户展示成为“dust”而非“flyway”。
一般来讲,这三个文件不需要 dust 使用者关心,故请不要去删除或修改它!!!关于部署脚本,很简单,继承 DustBaseMigration 就好了:
public class V1__CreateUser extends DustBaseMigration {
@Override
protected String[] files() {
return new String[]{
"./artifacts/myuser.sql" // 数据制品文件名
};
}
}
迁移脚本中要求实现的 files() ,其指定了数据库制品的执行顺序,甚至你也可以在 artifacts 目录下添加数据初始化文件,然后通过部署脚本完成部署。如:
@Override
protected String[] files() {
return new String[]{
"./artifacts/myuser.sql", // 创建 myuser 表
"./artifacts/insert_myuser.sql", // 插入数据
};
}
是不是有了点 Truffle Migration 脚本的感觉了?
由于迁移脚本采用的是 flyway 的 Java-based migrations ,若发现当前提供的 DustBaseMigration 类无法满足你的要求,请直接使用 flyway 提供的相应工具类。
哦,忘说了,dust 在迁移时会自动 baseline,同时设置迁移版本为 0,因此创建迁移脚本时 V 后的数字务必大于 0。
环境
这个简单,在项目模板中引入 dust-conf.json,形式如下:
{
"development": {
"url": "jdbc:postgresql://127.0.0.1:5432/earth_test?useUnicode=true&characterEncoding=utf8",
"user": "earth_admin",
"password": "admin"
},
"production": {
"url": "jdbc:postgresql://127.0.0.1:5432/jupiter_test?useUnicode=true&characterEncoding=utf8",
"user": "jupiter_admin",
"password": "admin"
}
}
是不是越来越像 Truffle 了,哈哈!
安装脚本
要将 dust 发布成命令行格式,还需完成最后一步:dust 运行脚本的编写,这里我们可以求助于 gradle 的 application 插件。它提供了几个任务自动完成相关工作:
- installdist,它将在工程的 build/install/dust/ 下安装,bin 目录下为可执行文件
- distTar/distZip,将生成 tar 或 zip 的安装包
模板工程的 build.gradle
最后说说模板工程的 build.gradle,因为它需要进行一些定制才能实现我们需要的目录结构:
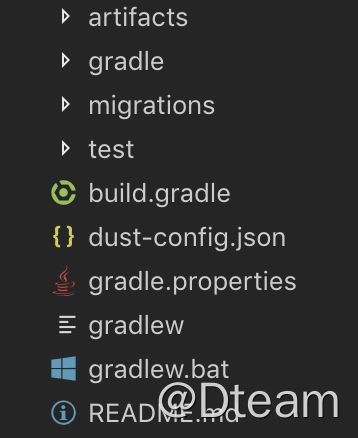
虽然是 gradle 工程(严格的说是 gradle groovy 项目工程,java 工程的超集),但是不是跟常见的目录结构不一样?这其中奥秘就在于下面两行:
sourceSets.main.groovy.srcDirs += ["migrations"]
sourceSets.test.groovy.srcDirs += ["test/groovy"]
总结
至此,整个 Truffle 的面向数据库开发的克隆版本就这样搭建完成了,挺好玩的吧,希望大家能喜欢。
觉得有帮助的话,不妨考虑购买付费文章来支持我们 🙂 :
付费文章