DTeam 技术日志
Doer、Delivery、Dream
土法炮制:Embedding 层是如何实现的?
在本系列的前面两篇文章(第一篇和第二篇)中,我们已经看到了如何用 TensorFlow 实现一些典型的神经网络层:Dense、Conv2D、MaxPooling、Dropout、Flatten。本文将介绍另一个典型层的实现:Embedding。
使用 Keras 的做法
同样,按照老规矩,先看看 Keras 的 Embedding 使用,然后再用 TF 实现。这里的示例也同样来自于一个常见的例子,imdb 评论分类。
import tensorflow as tf
from tensorflow.keras.datasets import imdb
from tensorflow.keras import preprocessing
max_features = 10000
maxlen = 20
# 加载数据
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=max_features)
# 预处理数据,将数据分割成相等长度
x_train = preprocessing.sequence.pad_sequences(x_train, maxlen=maxlen)
x_test = preprocessing.sequence.pad_sequences(x_test, maxlen=maxlen)
# 模型定义
model = tf.keras.models.Sequential([
tf.keras.layers.Embedding(max_features, 8, input_length=maxlen),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
# 训练
model.fit(x_train, y_train, epochs=10, batch_size=32, validation_split=0.2)
# 预测
print(y_train[:3])
print(model.predict_classes(x_test[:3]).flatten())
使用 TF 实现自定义结构
Embedding 本质上是一个全连接层,形式上,可以将其视为一个索引表,每一行对应一个单词相应的稠密向量,如下图(摘自 What the heck is Word Embedding ):
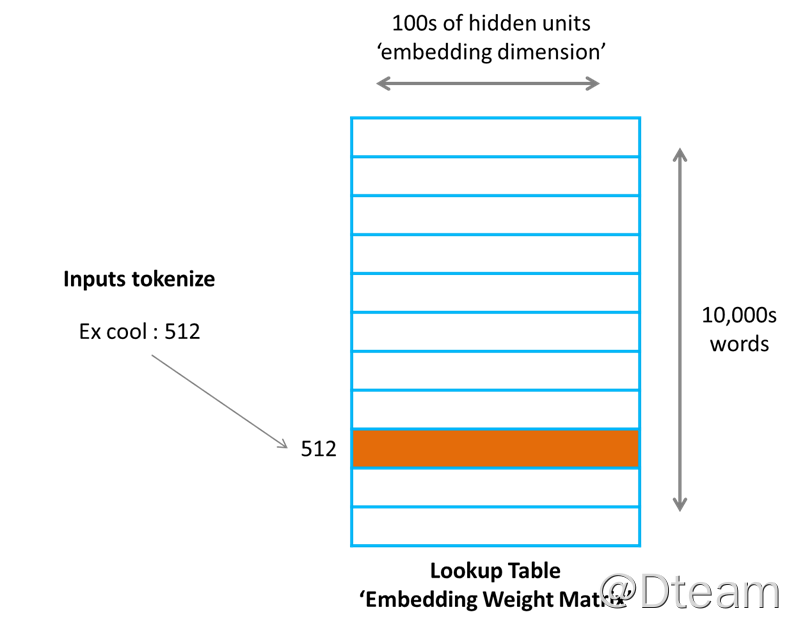
通常,会采用单词在文件中的索引来编码,因此从效果上来讲,one-hot 后跟一个全连接层等价于一个 embedding 层,因为相乘之后,得到值就是单词对应的向量,如下图(摘自 What the heck is Word Embedding ):
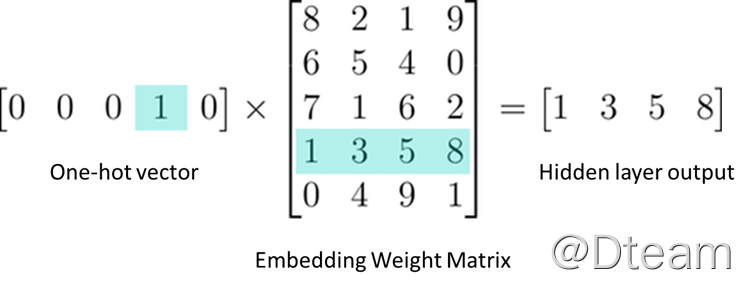
介绍完基本情况,那么接下来就看看如何实现吧。
MyDense
跟前几篇的代码差不多,换了一个激活函数。
class MyDense(Layer):
def __init__(self, units=32):
super(MyDense, self).__init__()
self.units = units
def build(self, input_shape):
self.w = self.add_weight(shape=(input_shape[-1], self.units),
initializer='random_normal', trainable=True)
self.b = self.add_weight(shape=(self.units,),
initializer='random_normal', trainable=True)
def call(self, inputs):
return tf.nn.sigmoid(tf.matmul(inputs, self.w) + self.b)
MyEmbedding
自定义 Embedding 层,注意:
- 继承 Layer 的规范,实现 build 和 call 。
- build 负责初始化权重和偏置,来自 Layer 。注意它们的 shape:
- 权重:单词个数 x Embedding 维数
- 偏置:无,因为不需要
- call 负责计算(返回对应 word index 的权重),来自 Layer 。
class MyEmbedding(Layer):
def __init__(self, input_unit, output_unit):
super(MyEmbedding, self).__init__()
self.input_unit = input_unit
self.output_unit = output_unit
def build(self, input_shape):
self.embedding = self.add_weight(shape=(self.input_unit, self.output_unit),
initializer='random_normal', trainable=True)
def call(self, inputs):
return tf.nn.embedding_lookup(self.embedding, inputs)
MyFlatten
跟上一篇差不多,shape 变了而已。
class MyFlatten(Layer):
def __init__(self):
super(MyFlatten, self).__init__()
def call(self, inputs):
shape = inputs.get_shape().as_list()
return tf.reshape(inputs, [shape[0], shape[1] * shape[2]])
MyModel
与前文代码差别不大,在更新准确率之前需要对预测值做变换。
class MyModel(Layer):
def __init__(self, layers):
super(MyModel, self).__init__()
self.layers = layers
def call(self, inputs):
x = self.layers[0](inputs)
for layer in self.layers[1:-1]:
x = layer(x)
return self.layers[-1](x)
def train(self, x_train, y_train, epochs = 5):
loss = tf.keras.losses.BinaryCrossentropy()
optimizer = tf.keras.optimizers.RMSprop()
accuracy = tf.keras.metrics.Accuracy()
dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
dataset = dataset.shuffle(buffer_size=1024).batch(64)
for epoch in range(epochs):
for step, (x, y) in enumerate(dataset):
with tf.GradientTape() as tape:
# Forward pass.
y_pred = model(x)
# Loss value for this batch.
loss_value = loss(y, y_pred)
# Get gradients of loss wrt the weights.
gradients = tape.gradient(loss_value, model.trainable_weights)
# Update the weights of our linear layer.
optimizer.apply_gradients(zip(gradients, model.trainable_weights))
# Update the running accuracy.
accuracy.update_state(y, tf.cast(y_pred >= 0.5, dtype=tf.int64))
print('Epoch:', epoch, ', Loss from last epoch: %.3f' % loss_value, ', Total running accuracy so far: %.3f' % accuracy.result(), end='\r')
print('\n')
搞定,接下来就看看效果了:
# 定义
model = MyModel([
MyEmbedding(max_features, 8),
MyFlatten(),
MyDense(1)
])
# 训练
model.train(x_train, y_train, 10)
# 预测
print(y_train[:20])
print(tf.cast(model(x_test[:20]) >= 0.5, dtype=tf.int64).numpy().flatten())
就结果而言,稍微有点过拟合,但基本可用了。
觉得有帮助的话,不妨考虑购买付费文章来支持我们 🙂 :
付费文章