DTeam 技术日志
Doer、Delivery、Dream
开发 Substrate 的准备工作
在前一篇,我们对“什么是 Substrate”有了感观上的认识,但这并不足以让你可以轻松地开发出符合自己需要的区块链。开发 Substrate 区块链应用也并非一个低门槛的工作,缺乏必备的知识将让人一头雾水摸不着头脑。
鉴于此,本文将作为一篇“过渡文章”,谈谈开发前的准备工作。至于实际的开发示例,将放在本系列的第三篇。
总的来讲,本文的内容将分为三部分:
- 需要了解的 Rust 知识
- 开发 Substrate 必备的基本概念
- Node-Template 基本结构
需要了解的 Rust 知识
开发 Substrate 应用, Rust 是开发人员必须迈过的第一道坎。然而,Rust 的学习曲线陡峭,入门并不简单,这里我稍稍整理了一下知识脉络,希望能减少大家的障碍。
对于 IDE,我建议大家不要把时间浪费在这个上面去做各种比较,先选择一个还不错的直接开始上手编写代码。我们的目标是尽快掌握 Rust 开发,不是去做工具的评测。本文推荐:vscode + rust 插件。如果你喜欢 IntelliJ IDEA,它同样也有 rust 插件。
同时,熟悉 Cargo,最好在写完 Rust 版 “Hello World!”后就尝试用 Cargo 去编译和构建。 必须要掌握的命令:
- cargo install
- cargo build
- cargo run
- cargo test
- cargo update
- cargo –list
对于每一个 Rust 工程,典型的过程如下:
- cargo new –binary,假设是可执行文件
- 编辑 cargo.toml 引入依赖
- 工程组织:
- main.rs + 各个 lib.rs
- src 目录下放源文件,单元测试与源文件在一起
- tests 目录下放集成测试
- cargo test
- cargo build —release
典型的 cargo 工程的目录组织如下图(摘自这里),并且也请重点理解一下 cargo workspace 的概念。

开发 Substrate 应用必须掌握的 Rust 语言基础知识(没列出的常规使用可以比照你已经掌握的语言):
- 宏的使用,但作为新手不要去纠结如何编写宏。
- 属性(Attribute)的含义和使用。
- 打印和 format! 的显示规范,尤其比如:{:?}
- 可变和不可变变量绑定,同时理解 & 以及 & mut,比如:String 和 &str 的区别。
- 典型集合类型:数组、Vector、Slice、Tuple。
- 静态结构定义和动态行为的添加:Struct + Traits 组合,同时了解 Trait 的类型约束,以及 + 和 where 的使用。
- 类型别名 type。
- 两类特殊的 Enum 类型:Option 和 Result。
- match 以及如何捕获 match 变量。
- 函数、闭包、高阶函数
- Rust 禁止隐式转换,实现类型之间转换的 From 和 Into Trait。
- 错误处理,以及 ? 的使用。
- 模块系统和 Crate。
真正让 Rust 大放异彩的实际上是跟内存安全相关的知识点:
- 理解指针和引用,有 C / C++ 的程序员应该不陌生。
- 理解 borrow 和 ownership。
- 变量直接赋值和类型的关系:
- 原始类型(标量类型、布尔、字符、数组、元组)或实现了 Copy Trait 的类型,赋值就是 copy,不涉及 ownership 转移
- 否则,ownership 将转移。
- 理解生命周期,熟悉 ‘static
- 利用 Drop Trait 释放资源,类似 C++ 的析构函数。
- 熟悉 Box、Rc、Cell、RefCell、Arc 等智能指针。
下图可以帮助大家理解 borrow 和 ownership,摘自 rust borrow 和 ownership 图解。
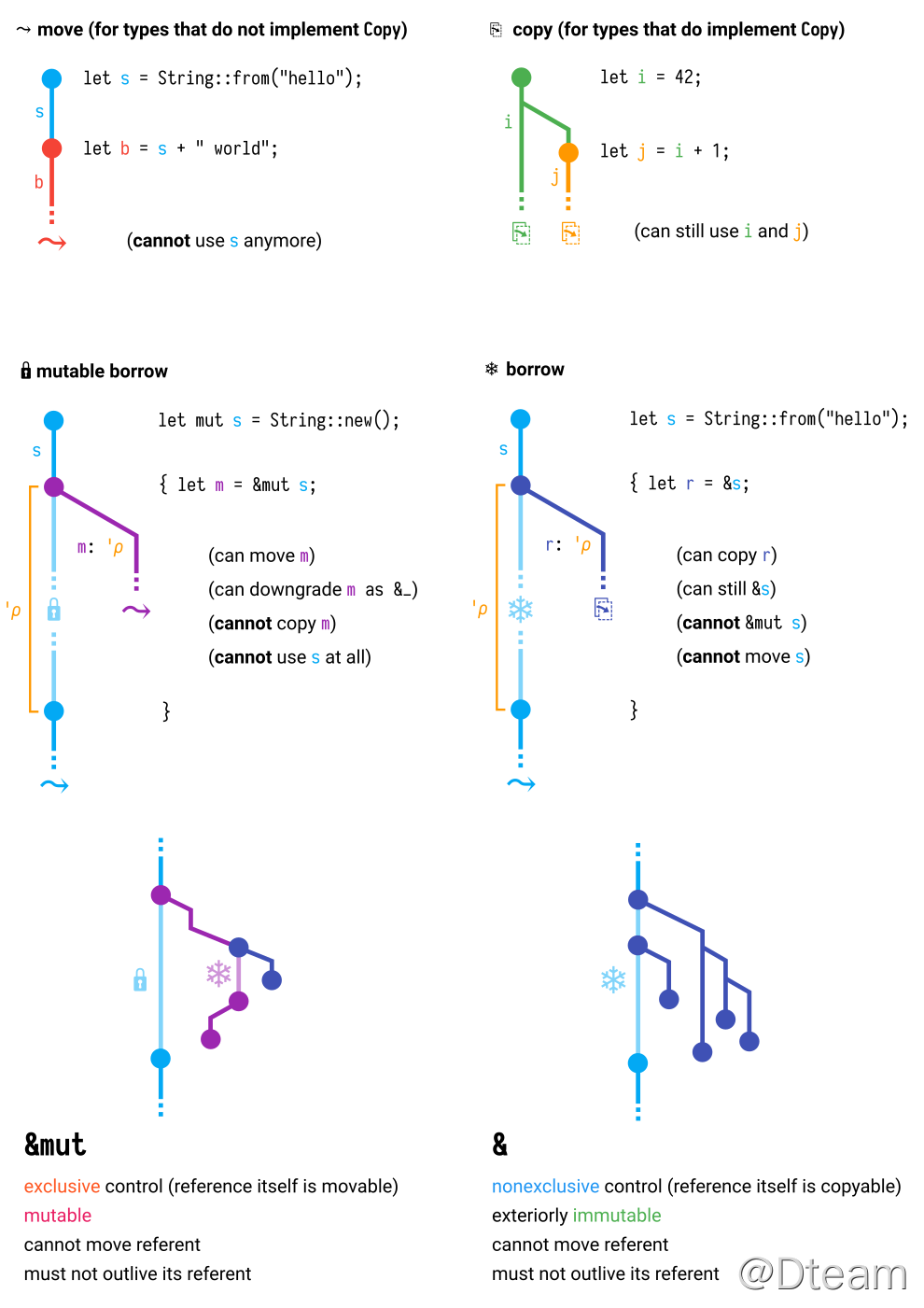
以上内容就是 Substrate 开发必备的 Rust 知识。当然,在开发过程中,还少不了要了解标准库和其他工具包的使用,但这些跟使用其他语言开发系统差别不大,在此略过不提。
至于其他功能,比如 GUI、网络、微服务、Web 和并发编程,有了以上的基础也能很快上手。
在结束本节之前,推荐几个链接:
最后,一个特别推荐:24 days of Rust。
开发 Substrate 必备的基本概念
前文说过,Substrate 可被视为区块链世界的 Spring Boot。既然如此,其文档就有必要至少通读一遍。话虽如此,但读文档并不是一件让人心情特别愉悦的事情,这里我列出主要纲要,希望能帮助各位快速建立全局概念,以便在读文档时可以更有针对性。
Substrate 的主要概念:
- extrinsics,上链信息(注:虽然社区将其称为【交易】,但个人觉得称其为【上链信息】更合适),来自链外,保存于区块之中。链上自己产生的事件不属于此列,它们统一被称为:intrinsics,链内信息。extrinsics 分为三类:
- inherents,无签名、直接插入,同时也不会在网络上传播或存在于 tx 队列。它们代表一类简单的“事实”,如时戳。
- signed tx,带有发起交易的账户的签名,在链上保存交易时需支付费用。等同于以太坊交易。
- unsigned tx,无签名,无 nonce,也无费用。使用时,需注意在交易队列中防止 spam。典型例子如:代表心跳的 tx。
- tx pool,包含所有已被本地节点接收并验证的广播到网络之上的交易(签名和未签名)
- tx pool 负责验证 tx 的有效性,其逻辑可配置。
- 若有效性得到验证,tx pool 将 tx 分为两组:ready queue,可直接插入到新块;future queue,未来有效的 tx,如 nonce 太高的 tx,它要等到前面 tx 被插入之后方能 ready。
- tx 的顺序和依赖有三个参数决定:requires(前提)、provides(输出)、priority(优先级)。
- tx weight,用于管理验证区块花费的时间,其中初衷是限制存储 IO 和计算,但对于存储本身和内存大小的管理并不是其目标。
- 账户抽象
- 两类账户
- stash key,大资金账户,私钥需要绝对安全,建议用冷钱包保存。
- controller key,授权账户,代表 stash 账户做决策,只保留必要的资金(如交易费用),私钥需要安全保存。
- session key,保存于验证者客户端,用来签名验证者操作,从不持有资金,也不是为资金用途服务。
- 两类账户
- offline worker,链下工作机,本质上相当于把预言机嵌入到了 substrate 节点中,集成更紧密,也越安全,使用上也越简单。其主要作用如下图,其运行环境也与 runtime 分离,互不干扰。
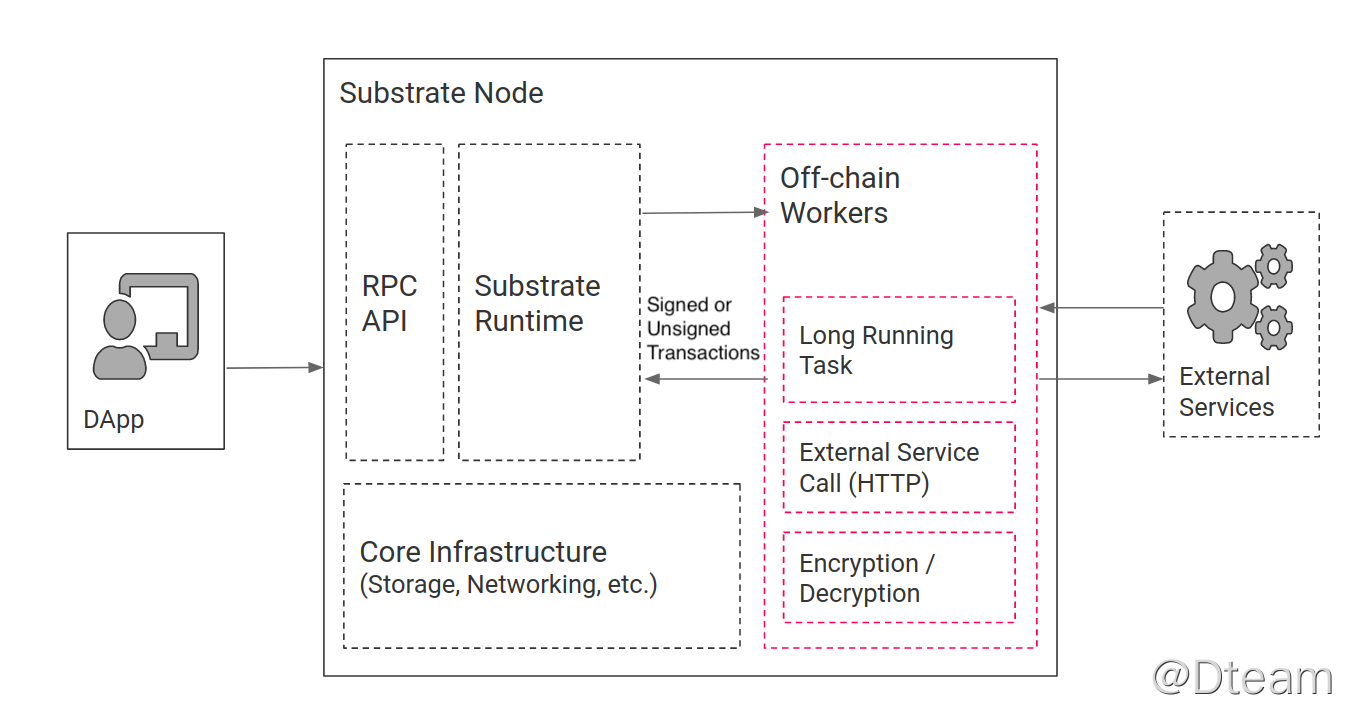
所谓开发 Substrate,其本质就是开发自己的 Runtime,它包含了区块链行为的业务逻辑,定义了用户可以派发的存储项和函数。每个 Runtime 包含了一组特定的 Pallet,每个 Pallet 定义了特定的功能业务逻辑以及所需的存储项。
Substrate 内置了一组预定义的 Pallet,这些 Pallet 及其支持库的全集被称为 FRAME。因此,FRAME 和 Runtime 的关系也就是全集和子集的关系,见下图。

当预定义的 Pallet 不足以满足业务需要时,开发者可以选择自行开发 Pallet。因此,整个开发工作也就成了:选择合适的 Pallet + 开发自己的 Pallet。
Pallet 的开发并没有想象中那么神秘,主要把握以下几点就行:
- 理解 Substrate 的数据类型,主要分为核心类型和 FRAME 类型。
- 理解 Pallet 的 5 个结构组合:依赖、配置、事件(通知外部)、存储(内部使用的存储项目)、声明(方便外部调用)。
- 熟悉相应的宏,它们充当了 DSL 的作用。
最后,就是掌握 Runtime 的构建,得到最终可用的 Node。至于如何与 Node 交互,只需查看对应的 client (如 polkadot.js)说明就好了,并不复杂。
Node-Template 基本结构
为了简化开发,Substrate 提供了工程模板:Node-Template。它本身是一个 cargo workspace,由三部分组成:
- node,定义整个节点的行为、cli、对外提供的服务,它是一个二进制工程,启动文件在此。
- runtime,自定义 Runtime,指定包含的 pallet,包括你定义的 pallet。它是一个 lib 工程。
- pallets,包含了 pallet 模板工程,一个 lib 工程。
整个 workspace 的级别依次是: node 包含 runtime 包含 pallet。并且,你可以创建多个 pallet,启用的话,则是将其在 runtime 中引用即可。
使用 pallets/template 开发 pallet 非常直观,基本上就是按照对应位置填写对应的逻辑就行了,关于具体做法,将在后文详述。
总结
希望本文能帮你建立对于 Substrate 开发的整体印象和直观感觉,虽说 Substrate 开发有一定的门槛,但毕竟不是火箭科学,熟悉 Rust 和 Substrate 的基本概念和结构之后,具体的开发跟其他应用系统的开发没有本质区别。
最后,在下一篇文章中,会展示一个实际的例子,同时演示如何与之交互,敬请期待,😄。
觉得有帮助的话,不妨考虑购买付费文章来支持我们 🙂 :
付费文章